Multisite adaption algorithm based on low-rank representaion: Criticizing a paper and developing my own algorithm, which is also full of flaws.
You may wanna read my note on low-rank representaion and the paper on multi-site adaption based on low-rank representation.
Part 1: Problems about this paper
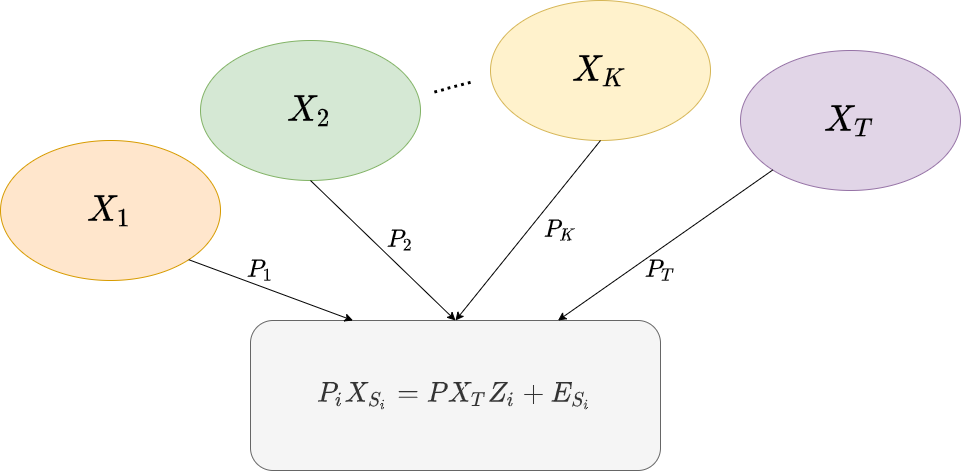
In the paper, the basic set up is: data come from T different sites, each site may have some systematic bias which make data from different sites somewhat "heterogeneous". Then from these T sites, choose one as "Target Site" ST, assume there is a projection matrix P which maps data from ST to the common latent space. Then for each of other sites Si, which are called a "Source Site", there is a projection matrix Pi, obtained by Pi=P+EPi, which maps data from Si to the latent space. Then use the mapped data from the target site to linearly represent the mapped data from source sites, that is PiXSi=PXTZi+ESi, where XSi is the data from source site Si and XT is the data from target site ST.The setup is illustrate by the picture below.
It's assumed that the latent space is low-rank, then the following optimization problem is given
minP,Pi,Zi,ESi,EPi ∣∣P∣∣∗+i=1∑K(∣∣Zi∣∣∗+α∣∣ESi∣∣1+β∣∣EPi∣∣1)s.t PiXSi=PXTZi+ESiPi=P+EPiPPT=I This problem can be solved by solving the equivalent problem
minP,J,Pi,Fi,Zi,ESi,EPi ∣∣J∣∣∗+i=1∑K(∣∣Fi∣∣∗+α∣∣ESi∣∣1+β∣∣EPi∣∣1)s.t PiXSi=PXTZi+ESiPi=P+EPiP=JZi=FiPPT=I Then the paper solve this problem with Augmented Lagrangian Multiplier. First, form the augmented lagrangian multiplier as if the constraint PPT=I does not exist.
Ac(P,J,Pi,Fi,Zi,ESi,EPi,Y1,i,Y2,i,Y3,i,Y4)= ∣∣J∣∣∗+i=1∑K(∣∣Fi∣∣∗+α∣∣ESi∣∣1+β∣∣EPi∣∣1) +<Y4,i,P−J>+i=1∑K(<Y1,i,Zi−Fi>+<Y2,i,PiXSi−PXTZi−ESi>+<Y3,i,Pi−P−EPi>) +2c∣∣P−J∣∣F2+2ci=1∑K(∣∣Zi−Fi∣∣F2+∣∣PiXSi−PXTZi−ESi∣∣F2+∣∣Pi−P−EPi∣∣F2) Then the optimization algorithm is given
initialize all variables
while not convergence{
Fix other variables, minimize A_c over J
Fix other variables, minimize A_c over F_i
Fix other variables, minimize A_c over E_{S_i}
Fix other variables, minimize A_c over E_{P_i}
Fix other variables, minimize A_c over F_i
Fix other variables, minimize A_c over Z_i
Fix other variables, minimize A_c over P_i
Fix other variables, minimize A_c over P
Update dual variable Y_{1,i} += Z_i - F_i
Update dual variable Y_{2,i} += Z_i - F_i
Update dual variable Y_{3,i} += Z_i - F_i
Update dual variable Y_1 += Z_i - F_i
P = Orth(P) to satisfy PP^T = I
}
I found 3 fatal mistakes in this article.
1. About the objective
In this article, one term in the the objective of the optimization problem is ∣∣P∣∣∗, which is the sum of singular values of P. But when the equality constraint PPT=I is satisfied, we can perform singular value decomposition on P, we will get
PPT=UΣVT(UΣVT)T=UΣVTVΣUT=UΣ2UT=I Multiplie both sides by U, we get UΣ2=U Since Σ is a diagonal matrix, the only solution is that Σ=I. If so, P=UΣVT has nuclear norm n, then the term ∣∣P∣∣∗ is determined by PPT=I. So the term ∣∣P∣∣∗ in the objective is redundant.
2. About the optimization problem
The optimization algorithm given by this article is not quite justified.
They constructed the Augmented Lagrangian Multiplier as if the equality constraint PPT=I, which is a quadratic constraint, does not exist. After each iteration where the primal and dual variables are minimized over, the constraint PPT=I is satisfied by "bruteforcely" orthogonalizingP, this step changes P, thus P does not minimizes the lagrangian when other variables are fixed, so the convergence of augmented lagrangian multiplier does not hold any more.
If this algorithm does converge with some magic going on underneath, at least they can give some proof or say something like "we cannot prove the convergence but it does converge everytime in the experiment".
3. About the convexity
As I quote from the paper, "the optimization of Eq.(5) is convex and can be solved by iteratively updating each variable separately".
Even if we do not consider this equality constraint PPT=I, which is not included when forming augmented lagrangian multiplier, the equality constraint PiXSi=PXTZi+ESi, which is a quadratic equality constraint because of the appearance of variables P and Zi in the same term, makes the problem nonconvex.
Thus the optimization problem is in no sense convex due to a quadratic equality constraint. There are some convergence proof for augmented lagrangian multiplier on nonconvex problems, but the statement "the optimization of Eq.(5) is convex" is definitely wrong.
So, there are 2 possibilities
- I do not fully understand this paper, if you find where I was wrong, please email diqiudaozhezhuan@gmail.com, it really bothers me.
- This article is full of flaws.
When thinking through this article, I came up with my own idea, which turns out to be also a piece of garbage. But I still wanna write it down.
Part 2: My own idea.
Actually, my idea is very simple. Suppose datas from differents sites came from a common space, for each site Si, there is a projection matrix Pi which project the data to a common space, then perform low-rank representation in the common space.
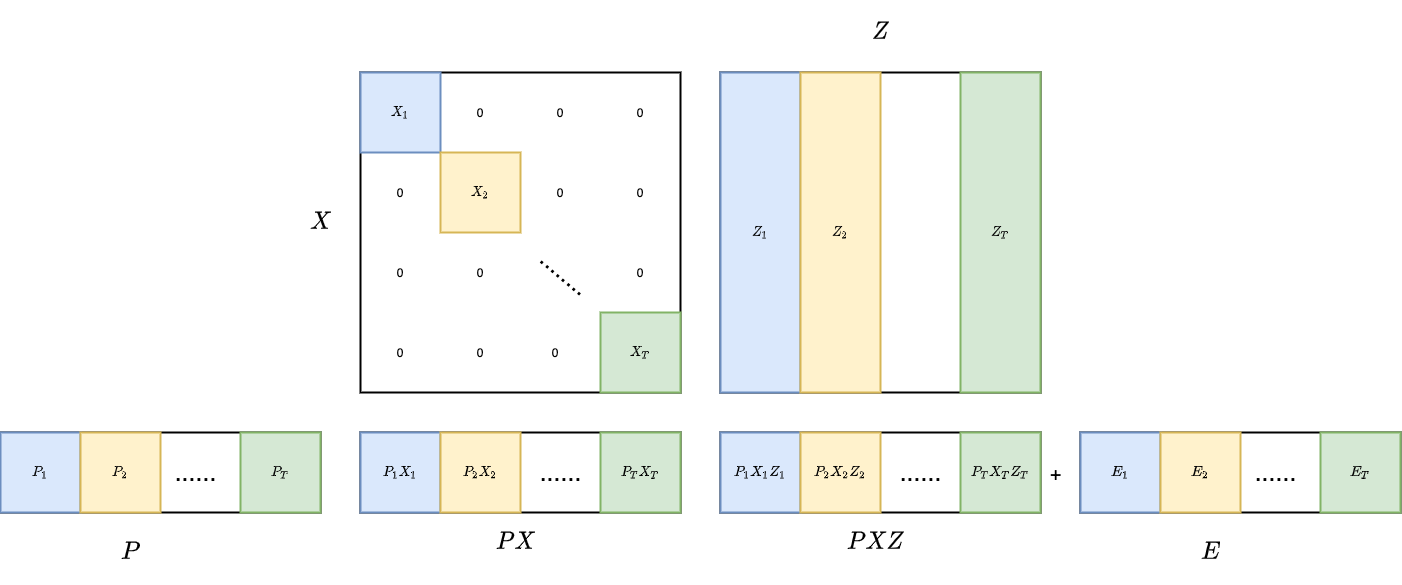
We can arrange Xi's into a block-diagonal matrix X and horizontally stack Pi's in to a matrix P. And the optimization problem can be written as
minP,Z,E ∣∣Z∣∣∗+λ∣∣E∣∣1s.t. PX=PXZ+E This is identical to the basic low-rank representation except that here we perform low-rank representation with PX. The structure of the matrix multiplication is shown in the picture below.
However, this optimization has a trivial solution P=0,Z=0,E=0. This trivial solution exists because that when mapping datas to a common space, we through all informations in X by setting P=0, thus the common space is surely low-rank. Thus, we want to project X into the common space and keep some information in X in the meantime. Consider the following optimization problem
minP,Z,E ∣∣Z∣∣∗+i∑(α∣∣Pi−I∣∣∗+β∣∣Ei∣∣1)s.t. PX=PXZ+E The term ∣∣Pi−I∣∣∗ in objective is quite heuristic, that is, put it other way, not fully justified. The motivation is, if ∣∣Pi−I∣∣∗ is small, then the sigular values of Pi−I tends to 0, then singular values of Pi tends to 1, thus we avoid the situation where Pi throws all information in X.
This problem is nonconvex due to the quadratic equality constraint PX=PXZ+E,but we can still use augmented lagragian multiplier to get to a local minimum.
To solve the optimization problem, we can solve the equivalent problem
minPi,Z,Ei,Qi,J ∣∣J∣∣∗+i∑(α∣∣Qi∣∣∗+β∣∣Ei∣∣1) s.t. PX=PXZ+E:Y1J=Z:Y2Qi=Pi−I:Y3,i First, we build the augmented lagrangian multiplier
A(Pi,Z,Ei,Qi,J,Y1,Y2,Y3,i)=∣∣J∣∣∗+i∑(α∣∣Qi∣∣∗+β∣∣Ei∣∣1) +<Y1,PX−PXZ−E>+<Y2,J−Z>+i∑<Y3,i,Qi−Pi+I> +2c∣∣PX−PXZ−E∣∣F2+2c∣∣J−Z∣∣F2+2ci∑∣∣Qi−Pi+I∣∣F2 We can alternatively minimize the lagrangian over each variable.
1. minimize over J
minJ A(Pi,Z,Ei,Qi,J,Y1,Y2,Y3,i) This gives the optimization problem
minJ ∣∣J∣∣∗+<Y2,J−Z>+2c∣∣J−Z∣∣F2 The close-form solution is given by singular value shrinkage
J=D1/c(Z−cY2) (1) 2. minimize over Qi
minQi A(Pi,Z,Ei,Qi,J,Y1,Y2,Y3,i) This gives the optimization problem
minJ α∣∣Qi∣∣∗+<Y3,i,Qi−Pi+I>+2ci∑∣∣Qi−Pi+I∣∣F2 The close-form solution is given by singular value shrinkage
Qi=Dα/c(Pi−I−cY3,i) (2) 3. minimize over P
minP A(Pi,Z,Ei,Qi,J,Y1,Y2,Y3,i) This gives the optimization problem
minP 2c∣∣PX−PXZ−E∣∣F2+2ci∑∣∣Qi−Pi+I∣∣F2 +<Y1,PX−PXZ−E>+i∑<Y3,i,Qi−Pi+I> This problem can be dissect into several optimization problems
minPi ∣∣PiXiFi+j̸=i∑PjXjFj−E∣∣F2+2ci∑∣∣Qi−Pi+I∣∣F2 +<Y1,PiXiFi>+i∑<Y3,i,Qi−Pi+I> where Fi is the ith row block of I−Z.
The close-form solution is given by
Pi[(XiFi)(XiFi)T+I]=(Qi+I+cY3,i)−(G+cY1)(XiFi)T (3) 4. minimize over Z
minZ A(Pi,Z,Ei,Qi,J,Y1,Y2,Y3,i) This gives the optimization problem
minZ2c∣∣PX−PXZ−E∣∣F2+2c∣∣J−Z∣∣F2 +<Y1,PX−PXZ−E>+<Y2,J−Z> The close-form solution is given by
[(PX)T(PX)+I]Z=(PX)T[PX−E+cY1]+J+cY2 (4) Implementation details: In (3) and (4),the "diagonal-plus-lowrank" structure is crying out, make sure that you exploit the sparsity pattern by using block elimination to solve the linear system
5. minimize over E
minE A(Pi,Z,Ei,Qi,J,Y1,Y2,Y3,i) This gives the optimization problem
minE β∣∣E∣∣1+2c∣∣PX−PXZ−E∣∣F2+<Y1,PX−PXZ−E> This problem can be dissected into several problems
minEi β∣∣Ei∣∣1+2c∣∣PXFi−Ei∣∣F2+<Y1,i,−Ei> where Fi is the ith column block of IZ, Y1,i is the ith column of the dual variable Y1.
This problem can be formulated as below
minEi cβ∣∣Ei∣∣1+21∣∣Ei−(PXFi+cY1,i)∣∣F2 which can be solved efficiently with primal-dual interior point method. For the detail, please refer to and appendix.
We can alternatingly optimize over each variable and update the dual variable accordingly in each iteration of augmented lagrangian multiplier.
This method also have some problems.
1. About the objective
The term ∣∣Pi−I∣∣∗ make the singular values of Pi tend to 1. However, we have no idea that the "right" solution for P have all 1 singular values. We can only prevent P from throwing away all information inX.
2. About the convexity
Due to the equality constraint PX=PXZ+E, the problem is nonconvex. Though we can get a local minimum by using the augmented lagrangian multiplier and achieve a "fairly good" solution by running multiple trials with different initial points, it's not as elegant as a convex problem.
3. About the complexity
In each iteration, assuming there are K sites and each data has dimension n, we'll need to solve K n×n SVDs when calculating (2), each of which has complexity O(n3). When the data is high-dimension, the problem becomes intractable quickly.
Part 3: Results of my own idea.
Following is the result on Yale face dataset when I set α=0.5 and β=0.05.



These images have lower quality after low-rank representaion, but remember that the purpose of low-rank representation if to map data into a common space. In these results, the shade at the eye is eliminated in the first image and the shade near the nose is eliminated in the second image, making those two images pretty "homogeneous".
Only one experiment was done since solving the optimization problem is pretty time-consuming. I think the result can be better if proper α and β is chosen.
4. Appendix : Solving one-norm-plus-frobenius-norm-square
Consider the optimization problem
minx k∣∣x∣∣1+∣∣x−v∣∣22 This can be reformulated into an equivalent problem
minx,y k1Ty+∣∣x−v∣∣22s.t. −y<=x<=y which is differentiable.
Write this into a standard form
min[x,y] k(0,1)(xy)+∣∣(I,0)(xy)−v∣∣22 s.t. (−II−I−I)(xy)≤(00) with a change of notation, we can write the problem as
minx cTx+∣∣Ax−b∣∣22s.t. Dx<=0:λ Form the Lagrangian
L(x,λ)=cTx+xT(ATA)x−2(ATb)Tx+bTb+λTDx the modified KKT condition for the log barrier is
{∇Lx(x,λ)=c+2ATAx−2ATb+DTλ=0−diag(λ)Dx=t11 The residual is given by
r(x,λ)=(c+2ATAx−2ATb+DTλ−diag(λ)Dx−t11) Then form the KKT system
(2ATA−diag(λ)DDT−diag(Dx))(dxdλ)=−(c+2ATAx−2ATb+DTλ−diag(λ)Dx−t11)=(−rd−rc) where rd and rc stand for dual residual and centrality residual, respectively. Then solve the KKT system by block elimination
(2ATA−DTdiag(Dx)−1diag(λ)D)dx=−rd−DTdiag(Dx)−1rc diag(λ)Ddx+diag(Dx)dλ=rc For more detail about primal-dual interior point method, refer to my note.
Implementation details: Notice the structure of matrices and make sure you exploit the sparsity in solving the KKT system.