KL Divergence
In this note we'll learn KL Divergence, which is an important concept in Machine Learning. I'll use the example found at here, but there's something I'd like to share in detail.
Problem we try to solve
Think about it. A group of astronauts find a planet where lives space worms. Their teeth are their weapons. The astronauts risked their life and did some sampling on the teeth number of worms of a total number of 100. And the result is like
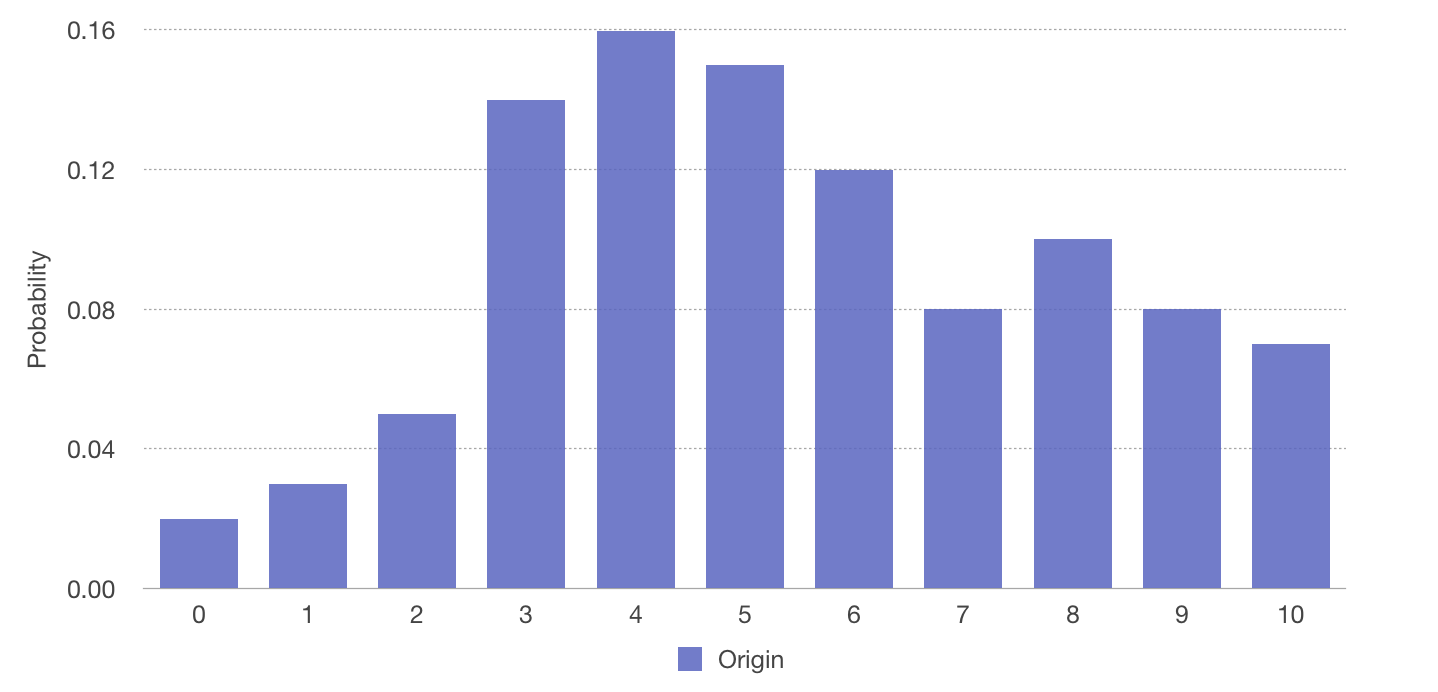
And to estimate the risk the astronauts will face, we want to fit the sample to a probability distribution, so that they can roughly know how scary a monster they'll meet.
First try, Uniform Distribution
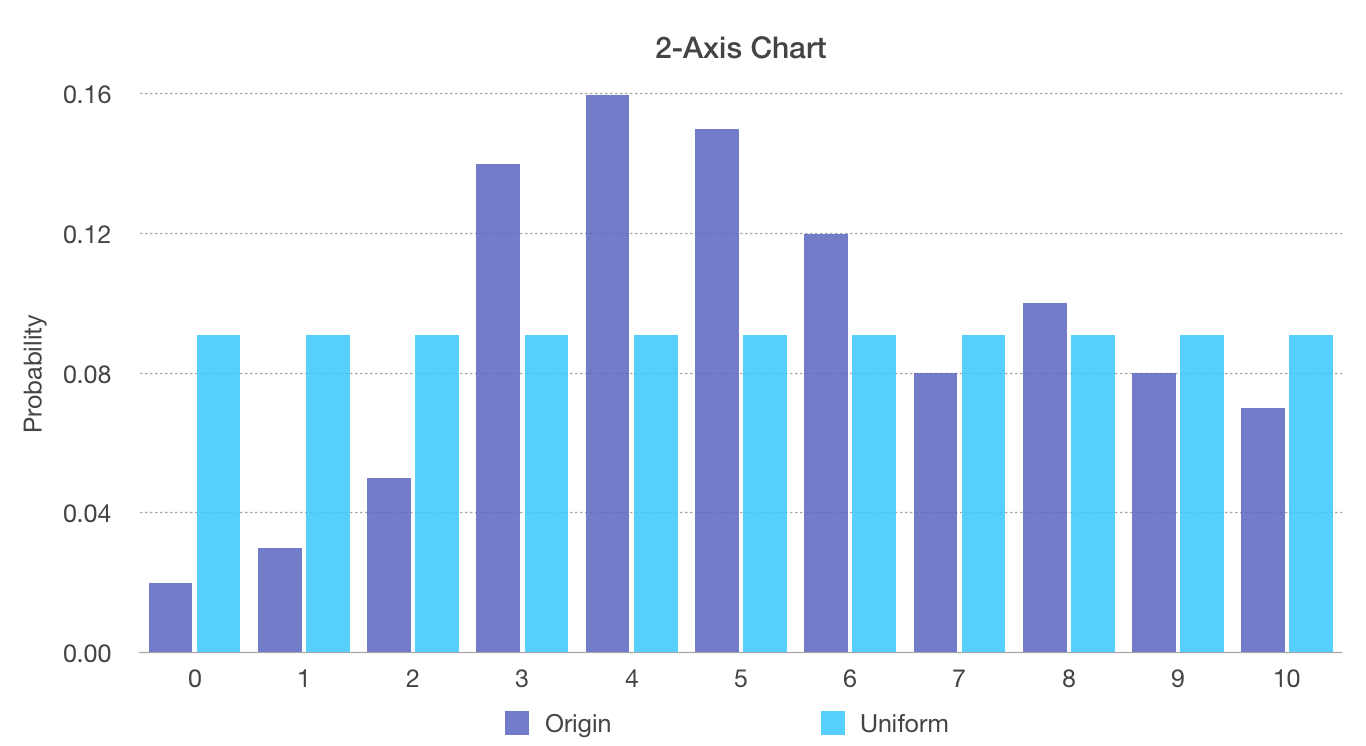
First, we try to fit this sampling to a Uniform Distribution.
Uniform Distribution has only one parameter, the probability of a given event happening.
Put original and the uniform distribution we fit together
Second try, Binormial Distribution
In Binomial Distribution, we enumerate each possible tooth as "there is" and "there isn't". For each possible tooth, the pobability of "there is" is
given by parameter , and the probability of "there is k teeth" is given by
where
The intuition is that first we pick k teeth from n positions, and for each of k existing teeth, the probability of "there is" is ; and otherwise the probability of "there isn't" is .
Additionally, for n example, the expected(mean) value of a binormial distribution is ,that is, if you toss a coin for times and each toss the probability of getting head is , if you do the experiment for times, will be , or say, for each expriment, it's expected to heads.
And the variance is . Suppose we toss a coin which follow a binomial distributionfor n times and probability we calculate of getting a head is . The variance is given by formula(suppose that head is 1 and tail is 0)
And now back to modeling. For wach space worm, it's like a 11-time-toss(11 is the largest number of teeth), and each tooth of a space worm is a toss. So the expected value(mean) is
So the probability of a 0-tooth worm is
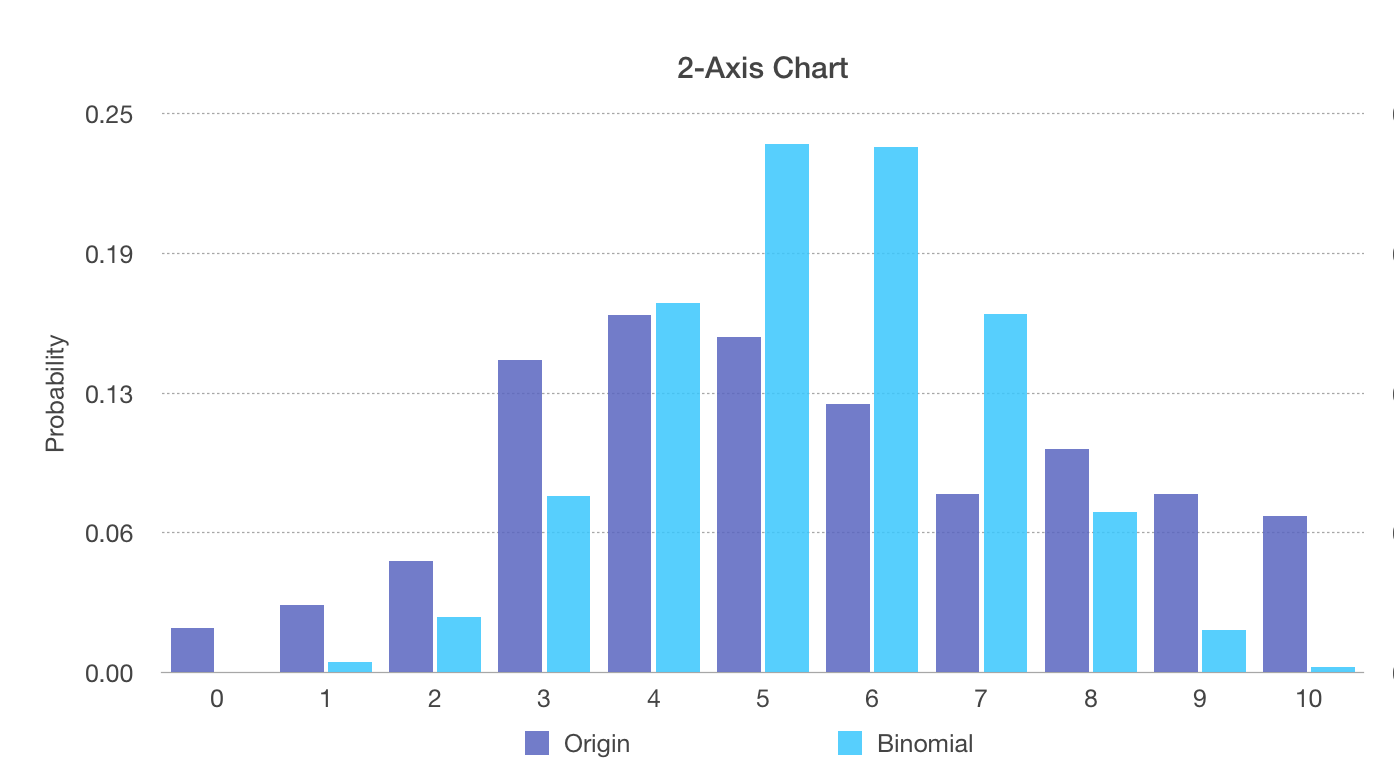
Put original distribution and binomial distribution together, it looks like
Put all these three distributions together.
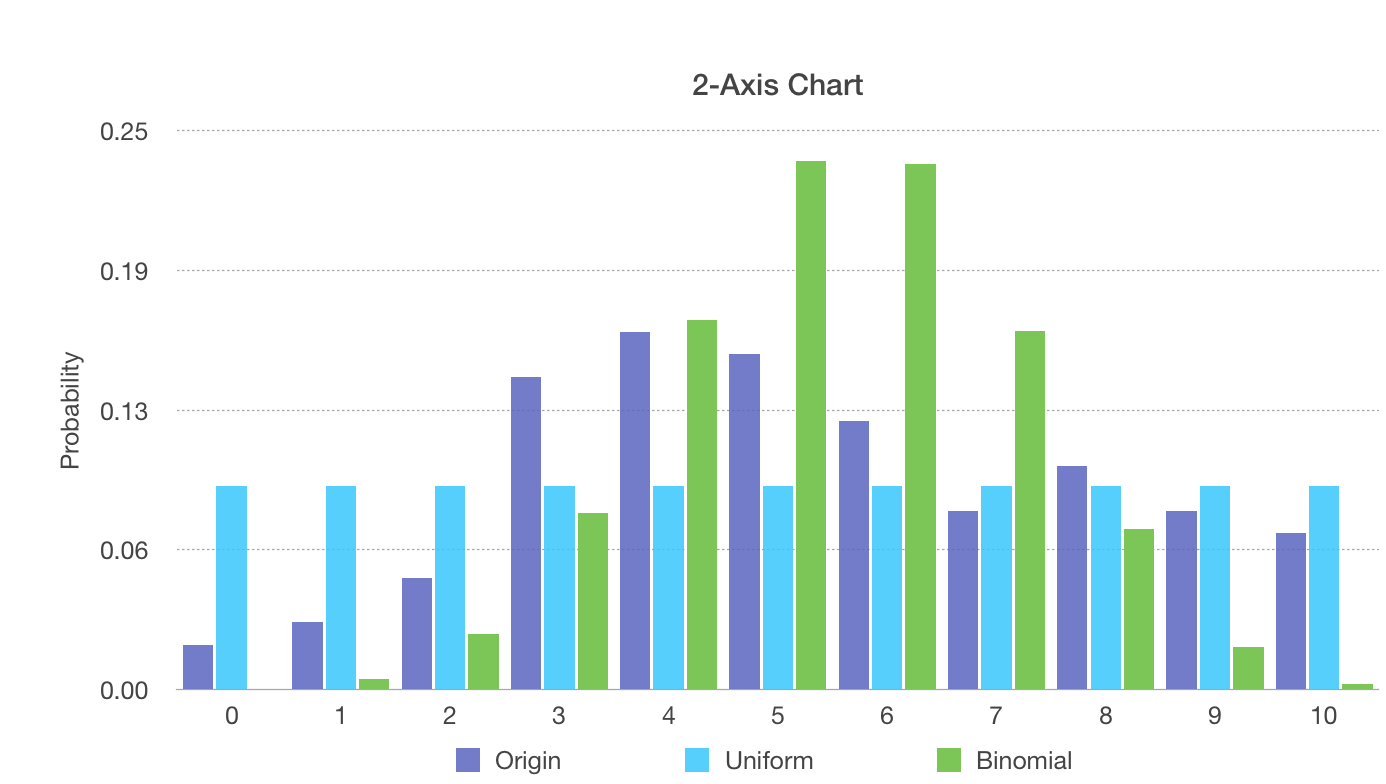
KL Divergence
Now we fit the original probability distribution to 2 uniform distribution and binomial distribution, we want to pick the one with better fitting, but how to me measure which one is better? That's where KL Divergence comes in.
Let's assume the original distribution is and the distribution we fit is .
The KL divergence is defined as
The intuition is, indicates how much differs from , and maps the difference to a zero-based number, the closer is to , the less the term is; when , the term is 0. And the before the terms shows how much the difference at matters to the whole distribution, if is almost , it doesn't matter much even if differs a lot from .
And now, back to our two distributions, which one is a better fit?
First let calculate with python.
import numpy as np
uniform = []
for i in range(11):
uniform.append(0.0909)
uniform = np.array(uniform)
binomial = np.array([
0.0004,
0.0046,
0.0248,
0.0792,
0.1653,
0.2367,
0.2353,
0.1604,
0.0717,
0.019,
0.0023
])
real = np.array([
0.02,
0.03,
0.05,
0.14,
0.16,
0.15,
0.12,
0.08,
0.1,
0.08,
0.07
])
Now we need a function to calculate KL divergence from two distributions. Remeber the formula is
def KL_Divergence(dis1, dis2):
ret = 0.0
for i in range(len(dis1)):
ret += dis1[i] * np.log(dis1[i]/dis2[i])
return ret
DL_real_uniform = KL_Divergence(real, uniform)
DL_real_binomial = KL_Divergence(real, binomial)
print "KL(real||uniform): ", DL_real_uniform
print "KL(real||binomial): ", DL_real_binomial
The output is
KL(real||uniform): 0.13677971595000277
KL(real||binomial): 0.42657918710043913
Actually, the uniform distribution is a better fit.