Entropy & Infomation Gain
Entropy
Entropy(熵) indicates the uncertainty of a random variable.
Suppose X is a discrete random variable with finite value, it's probability distribution is
Then the entropy of X is defined as
From the definition we know that the entropy only relates to X's distribution, not X's value.
Greater uncertainty leads to greater entropy.
Take Bernoulli Distribution as an example.
Suppose we have a Bernoulli Distribution pramaterized by p .
The entropy of X is
Looks like
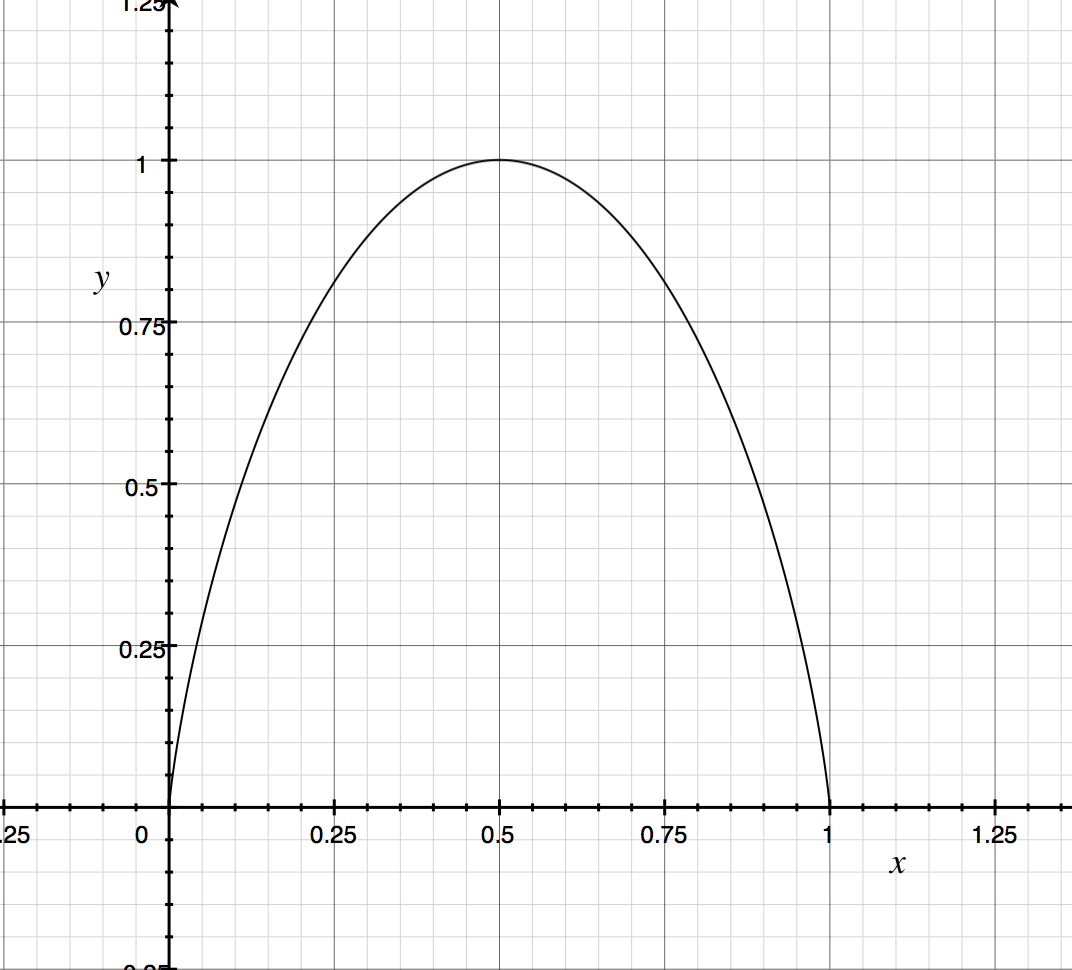
When or , entropy is 0, or say, there's no uncertainty, and when , the uncertainty get it's maximum.
Conditional Entropy
Suppose random variable, it's joint probability distribution is
Conditional Entropy indicates uncertainty of random variable Y given random variable X, defined as
mathematical expectation of respect to X
When probability is get from data approximation(especially Max Likelihood), corresponding entropy and conditional entropyis called empirical entropy and empirical conditional entropy.
Infomation Gain
Infomation Gain indicates how much get infomation of feature decrease the uncertainty of class .
Infomation Gain of feature to training dataset is defined as difference of 's empirical entropy and empirical conditional entropy given feature
Intuitively, and literally, information gain is how much knowledge about we get from giving .
When build decision tree, we always want to get more information from one single given feature.